Article Text

Abstract
Introduction To assess the comparative effectiveness and safety of renal-related outcomes associated with sodium-glucose cotransporter-2 inhibitors (SGLT2-i) initiation among patients with type 2 diabetes using real-world data.
Research design and methods We conducted a population‐based cohort study using administrative healthcare data from Alberta (AB), Canada and primary care data from the Clinical Practice Research Datalink (CPRD), UK. From a cohort of new metformin users, we identified initiators of a SGLT2-i or dipeptidyl peptidase-4 inhibitor (DPP4-i) between January 1, 2014 and March 30, 2018 (AB) or between January 1, 2013 and November 29, 2018 (CPRD). Initiators of an SGLT2-i or DPP4-i were followed until death, disenrolment, therapy discontinuation, or study end date. The effectiveness outcome was renal disease progression, defined as a composite of new-onset macroalbuminuria, serum creatinine doubling with estimated glomerular filtration rate of ≤45 mL/min/1.73 m2, renal replacement therapy, hospital admission or death from renal causes. The safety outcome was hospitalization due to acute kidney injury (AKI). We adjusted for confounding using high-dimensional propensity score matching and estimated HRs using Cox proportional hazards regression. Aggregate data from each database were combined by random-effects meta‐analysis.
Results Among the 29 465 included patients (20 564 AB, 8901 CPRD), 37.5% were new SGLT2-i users in AB and 21.3% in CPRD. Compared with DPP4 initiators, SGLT2-i initiators were associated with a reduced risk of renal disease progression (pooled HR 0.79, 95% CI 0.62 to 1.00); however, there was no significant difference in the risk of AKI (pooled HR 0.89, 95% CI 0.58 to 1.36). These findings were consistent with other exposure definitions and antidiabetic comparators.
Conclusions Our findings support a renoprotective effect of SGLT2-i without an increased risk of AKI, compared with clinically relevant active comparators.
- diabetes complications
- pharmacoepidemiology
- kidney diseases
Data availability statement
Data may be obtained from a third party and are not publicly available. We are unable to make data available because of third party license restrictions.
This is an open access article distributed in accordance with the Creative Commons Attribution Non Commercial (CC BY-NC 4.0) license, which permits others to distribute, remix, adapt, build upon this work non-commercially, and license their derivative works on different terms, provided the original work is properly cited, appropriate credit is given, any changes made indicated, and the use is non-commercial. See: http://creativecommons.org/licenses/by-nc/4.0/.
Statistics from Altmetric.com
Significance of this study
What is already known about this subject?
Evidence from randomized clinical trials supports a protective effect the sodium-glucose co-transporter 2 (SGLT-2) inhibitors on renal disease progression among patients with and without type 2 diabetes, without increasing the risk of acute kidney injury (AKI).
Further evidence from population-level ‘real-world’ practice data to support the effectiveness and safety of the SGLT-2 inhibitors is warranted.
What are the new findings?
Compared with other classes of antidiabetics, new use of SGLT-2 inhibitors was associated with a 20%–40% lower risk of renal disease progression, defined as a composite of new-onset macroalbuminuria, serum creatinine doubling with estimated glomerular filtration rate of ≤45 mL/min/1.73 m2, renal replacement therapy, hospital admission, or death from renal causes.
In five head-to-head comparative cohorts with other classes of antidiabetics, new use of SGLT-2 inhibitors is not associated with an increased risk of hospitalizations from AKI.
These renal effectiveness and safety findings did not differ between canagliflozin, dapagliflozin, or empagliflozin, suggesting a class-effect.
How might these results change the focus of research or clinical practice?
Consistent with findings from placebo-controlled randomized controlled trials, these results support a renoprotective effect of SGLT-2 inhibitors without an increased risk of AKI, compared with active comparators.
This study provides reassurance to clinicians on the effectiveness and safety of SGLT-2 inhibitors in a broad group of patients in an unrestricted routine clinical practice setting.
Introduction
Sodium-glucose cotransporter-2 (SGLT-2) inhibitors are a class of antihyperglycemic medications used for type 2 diabetes management that exert their effect by altering renal physiology. Specifically, these agents increase the urinary excretion of filtered glucose by inhibiting its reabsorption by the SGLT-2 proteins in the proximal renal tubules.1 Evidence from clinical trials has shown SGLT-2 inhibitors to be cardioprotective and renoprotective in a manner that is above and beyond their glucose-lowering effect.2–4 Several direct and indirect mechanisms have been hypothesized to explain these clinically relevant benefits, including improved glomerular hyperfiltration, ketogenesis promotion, blood pressure reduction, erythropoiesis, improved cardiac energy metabolism, uric acid and inflammation reduction, and weight loss.5–7 Furthermore, SGLT-2 inhibitors have shown to reduce the risk of development or worsening of albuminuria, a marker of glomerular damage.8 9 Given the burden of diabetic nephropathy as a chronic complication of diabetes and a leading cause of death, this renal protective effect deems SGLT-2 inhibitors as a valuable therapeutic option and potentially explains their increased utilization rates.10–12
Despite these demonstrated renal benefits, SGLT-2 inhibitor use has been linked with an increased risk of acute kidney injury (AKI) by case reports, leading to a series of safety warnings by several regulatory bodies.13 14 This was hypothesized to be due to volume depletion and systematic blood pressure reduction resulting from the SGLT-2 inhibitor-induced glucosuric osmotic diuresis.15 However, available evidence does not support an increased risk of AKI compared with placebo or other antidiabetic agents.16 17 In fact, a meta-analysis of randomized controlled trials (RCTs) found a consistent reduction in the risk of AKI among the SGLT-2 inhibitor group compared with placebo.18
Thus far, evidence on the effect of SGLT-2 inhibitors on renal disease progression relies almost exclusively on evidence from RCTs.19–22 Evidence from observational studies has used varied definitions of renal-related end points, restricted populations, and limited follow-up times.23–30 As such, real-world effectiveness and safety of SGLT-2 inhibitors requires further investigation. Herein, we aim to provide additional real-world evidence on both the renal effectiveness and safety of SGLT-2 inhibitors in patients with type 2 diabetes. Specifically, we will quantify the risk of new or worsening nephropathy and AKI associated with the initiation of SGLT-2 inhibitors compared with clinically relevant active comparators.
Research design and methods
Study design and data source
We conducted a population-based retrospective cohort study using two population-based data sources: (1) administrative healthcare data from the province of Alberta (AB), Canada and (2) primary care clinical data from the UK’s Clinical Practice Research Datalink (CPRD) GOLD. AB’s administrative databases capture population-based universal healthcare system encounters for all AB residents (over 4 million). The CPRD contains longitudinal data on about 5% of the UK population collected from over 950 primary care practices, providing a representative sample that is similar to the overall UK population in age, sex, and ethnicity.31–35 Both data sources are routinely checked for accuracy through computerized validation checks.
From both sources, de-identified individual-level longitudinal data were available for: (1) sociodemographic (age, sex, and index of multiple deprivation (CPRD only)); (2) hospital-based diagnoses using the 10th revision of the International Statistical Classification of Diseases (ICD-10) codes; (3) medical diagnoses using ICD-9 in AB and Read codes in CPRD; (4) outpatient prescription medications (dispensation records from AB and prescription records from primary care physicians in CPRD); (5) laboratory data (eg, renal function, lipids, blood glucose, etc) and (6) mortality data (date and cause of death). Hospital episode and death certificate linkage is only available for a subset of CPRD data. Additionally, physiological information (body mass index (BMI)) and information on health behaviors (eg, smoking) were also retrieved from CPRD.
Study cohort
First, we identified a base cohort of adult (≥18 years) new users of metformin as monotherapy, between January 1, 2012 (AB) or January 1, 2005 (CPRD) and the end of study period (March 30, 2018, in AB and November 29, 2018, in CPRD). New metformin users were defined as those with no prescription records for any antidiabetic drug, including insulin, for 365 days prior to the initial metformin prescription. At least 12 months of continuous data prior to the first antidiabetic agent prescription recorded during the study period was required. We restricted the CPRD cohort to patients eligible for linkage to hospital records through the Hospital Episodes Statistics (HES) and death certificate records through the Office of National Statistics (ONS) (herein referred to as HES/ONS linkage). From the base cohort, we identified all patients initiating either an SGLT-2 inhibitor or a DPP4 inhibitor between May 1, 2014 in AB or January 1, 2013 in CPRD (corresponding to after market entry in Canada and the UK), and the end of study period. We included patients who have been exposed to other antidiabetic drugs (not SGLT-2 inhibitor or DPP4 inhibitors) before index date. Furthermore, we excluded patients who have a previous record of diagnostic codes indicating AKI or renal replacement (dialysis or transplant) in the 365 days before initiation of an SGLT-2 or DPP4 inhibitor.
Exposure and outcome definitions
SGLT-2 inhibitor and DPP4 inhibitor exposure was operationalized using an as-treated exposure definition. The index date of exposure was defined as the date of initiation of SGLT-2 inhibitor or DPP4 inhibitor. We calculated the duration of therapy for each prescription based on the quantity dispensed (or days’ supply if available) plus a 30-day grace period to account for non-adherence. If quantity was missing, we assumed a 30-day supply. For the primary analysis, gaps between prescriptions were allowed, although we conducted several sensitivity analysis whereby alternative exposure definitions were used. Discontinuation of exposure was based on the estimated duration of the last SGLT-2 or DPP4 inhibitor prescription plus a 30-day grace period.
The primary efficacy outcome was a composite of new or worsening nephropathy, defined as either (1) increase from baseline, defined as the latest laboratory value measured before index date, in 24-hour urinary excretion of albumin to >300 mg OR increase in timed collection to >200 μg/min OR increase in albumin-creatinine ratio (ACR) to >20 mg/mmol; (2) a doubling of the serum creatinine level from baseline, accompanied by an estimated glomerular filtration rate (eGFR) of ≤45 mL/min/1.73 m2; (3) the initiation of renal replacement therapy, based on hospitalization records; (4) new hospitalization for renal failure or (5) death from renal disease. This definition was based on the (Empagliflozin) Cardiovascular Outcome Event Trial in Type 2 Diabetes Mellitus Patients (EMPA-REG OUTCOME) trial.20 For laboratory test-based end points, baseline values were compared with one or more measures during follow-up and the first date any lab-based end point (ie, albuminuria) criteria was met was considered the outcome event date.
The primary safety outcome was AKI based on all hospitalization records for one of the following ICD-10 diagnostic codes: N17.0, N17.1, N17.2, N17.8 or N17.9. Previous studies have shown this case definition has a specificity of >95%.36–38
Propensity score matching
To minimize potential confounding, we used propensity score matching. We used the high dimensional propensity score algorithm39 to identify relevant potential confounders based on five dimensions (hospitalizations, procedures, medical diagnoses, prescription medication, and laboratory records) during the year before index date. A sixth dimension, emergency department visits, was also included for the AB analysis. We identified the 200 most prevalent variables in each dimension and ranked them according to their frequency as once, sporadic or frequent. Then, we selected 500 variables for inclusion in estimation of propensity score, in addition to a list of 30 predefined variables (32 in CPRD), including sex, age, year of cohort entry, prescription drug use (ACE inhibitors, angiotensin receptor blockers, statins, loop diuretics, thiazide diuretics, other antihypertensive drugs, other antidiabetic agents, epoetin/darbepoetin), comorbidities (myocardial infarction, stroke, heart failure, hypertension, dyslipidemia, amputation, diabetic ketoacidosis, fracture, chronic kidney disease), laboratory values (hemoglobin A1c (HbA1c), eGFR, hemoglobin, high-density lipoprotein, low-density lipoprotein, triglycerides, ACR), in addition to physiological and lifestyle indicators (smoking, BMI) from CPRD only. A multivariable logistic regression model was used to estimate propensity scores for initiation of an SGLT-2 inhibitor compared with a DPP4 inhibitor. SGLT-2 inhibitor users were then matched to DPP4 inhibitors users in a one-to-one greedy nearest-neighbor match based on the logit of propensity score with a caliper of 0.2 times the SD.40 41 Balance of baseline covariates after matching was assessed using standardized differences (>10% considered unbalanced).42 We repeated the above propensity score matching process for each secondary and sensitivity analysis which are described below.
Primary analysis
Standard descriptive statistics were used to compare the characteristics of SGLT-2 inhibitor users with DPP4 inhibitor users. Patients were followed from index date until the earliest of experiencing the outcome, disenrolment, switching from SGLT-2 inhibitor to DPP4 inhibitor, switching from DPP4 inhibitor to SGLT-2 inhibitor, death, or cohort end date. Incidence rates per 1000 person-years were calculated before and after propensity score matching. The association between SGLT-2 inhibitor use and the renal outcomes of interest was assessed using a conditional Cox proportional hazards regression models, stratified by matched pair, within the matched cohort. We ran an additional multivariable conditional Cox model adjusted for age, sex, and the use of other antidiabetic agents in the year prior to index date. Model assumptions including the proportional hazards assumption for each variable was tested.43 Furthermore, we assessed for effect modification by age, sex, diabetes duration, and A1c level using an interaction term between exposure status and these variables. We considered a p value <0.05 to be statistically significant. Last, aggregate data from each database were combined by random-effects meta‐analysis using a profile likelihood estimator.44
Secondary and sensitivity analyses
For the secondary analyses, we repeated our primary analysis using four alternative active comparator new-user cohorts using the following control groups: sulfonylureas (SU), glucagon-like peptide-1 receptor agonists (GLP1- RA), thiazolidinediones (TZD), and insulin. For each of these analyses, a new cohort was identified, and the propensity score matching process was conducted. We also stratified the primary cohort (SGLT-2 inhibitors matched to DPP4 inhibitors) based on individual SGLT-2 inhibitor agents (canagliflozin, dapagliflozin, and empagliflozin). We conducted a stratified analysis for the primary cohort based on baseline kidney function, wherein we calculated the eGFR based on an abbreviated Modification of Diet in Renal Disease (MDRD) equation using the serum creatinine measurement most recent before index date, if there were no serum creatinine measurement before index date, we used the first measurement within 365 days after index date. The stratification cut-off point was eGFR <60 mL/min/1.73 m2 as impaired kidney function and ≥60 mL/min/1.73 m2 as non-impaired kidney function. Last, for our primary cohort, we replicated our primary analysis to assess the association for each of the five components of the composite outcome definition.
To test the robustness of our results, we took two main approaches to conduct a series of sensitivity analyses. First, we varied the definition of our exposure where we reran our primary analysis and secondary comparator analysis using the following exposure definitions: (i) as-treated exposure definition without allowing any gaps in exposure whereby we censored a person’s follow-up time at their first gap; (ii) intention to treat exposure definitions with a maximum follow-up of 180, 365, and 730 days; (iii) time varying exposure definition. Second, we reran our primary effectiveness analysis using the full CPRD GOLD cohort, irrespective of eligibility for HES/ONS linkage.
Data availability statement
Data may be obtained from a third party and are not publicly available. We are unable to make data available because of third party license restrictions.
Results
Study cohorts
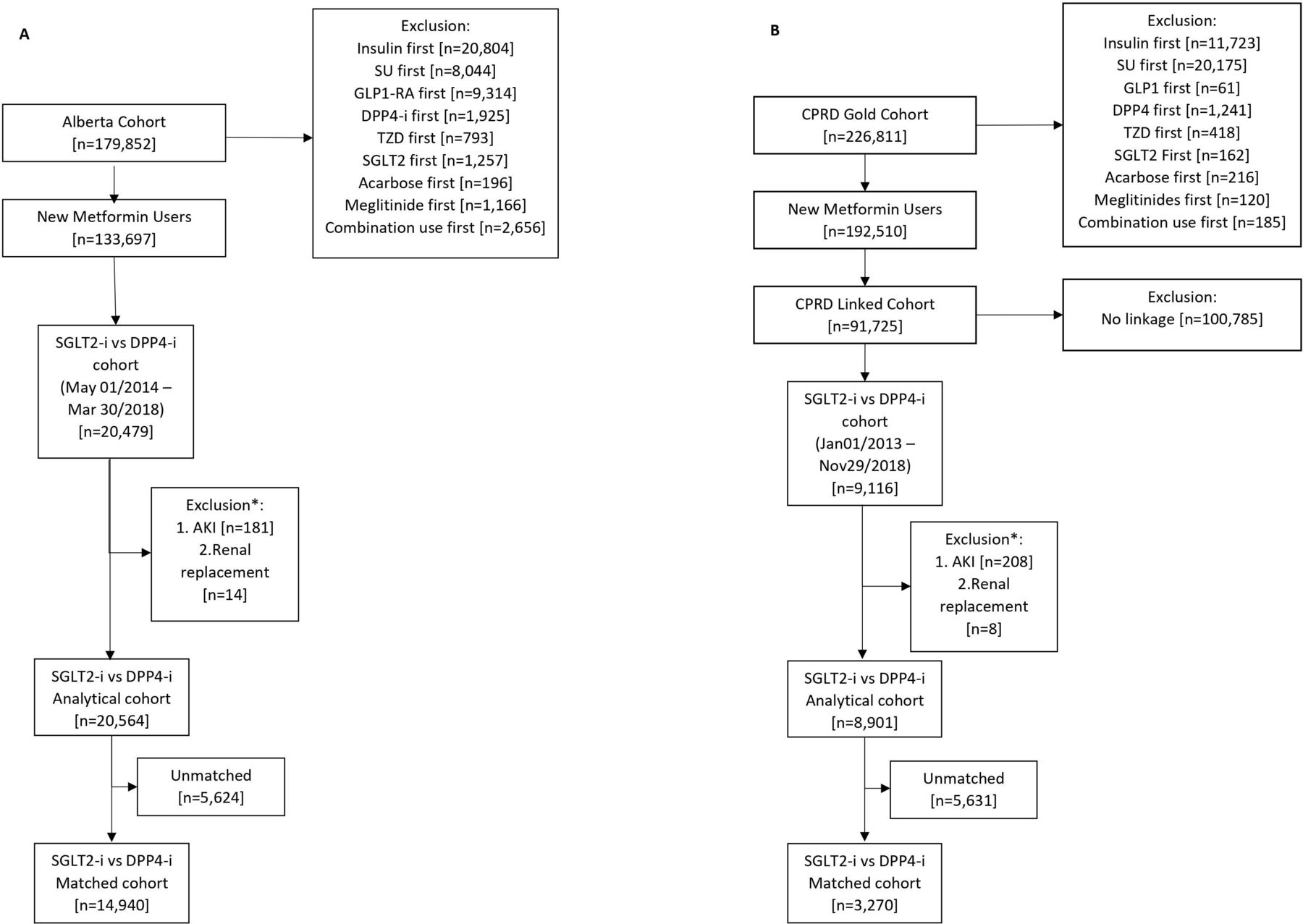
In AB, there were 20 564 new users of SGLT-2 or DPP4 inhibitors from which 7470 matched pairs were identified (figure 1A). In CPRD, there were 8901 new users of SGLT-2 inhibitors or DPP4 inhibitors from which 1635 matched pairs were identified (figure 1B). Patient characteristics were well balanced following propensity score matching in both study populations (online supplemental table 1). Additionally, we were able to assess the racial and ethnic backgrounds for the CPRD cohort only, which included 75.4% white, 3.3% South Asian, 1.4% black, 2.2% other, and 17.7% unknown for SGLT-2 inhibitors and 71.8% white, 3.2% South Asian, 2.4% black, 3.2% other, and 19.2% unknown for DPP4 inhibitors after matching. Study cohort flow diagrams to identify new users of SGLT-2 inhibitors or active comparator are reported in online supplemental figures 1–4) and patient characteristics of these cohorts are reported in online supplemental tables 2–5).
Supplemental material

Flow diagram to identify initiators of sodium-glucose cotransporter-2 inhibitors (SGLT2-i) and dipeptidyl peptidase-4 inhibitors (DPP4-i) in Alberta (A) and Clinical Practice Research Datalink (CPRD) (B). *Person may belong to >1 exclusion criteria. AKI, acute kidney injury; GLP1-RA, glucagon-like peptide-1 receptor agonists; SU, sulfonylureas; TZD, thiazolidinediones.
Renal disease progression
In AB, there were a total of 157 events among SGLT-2 inhibitor users and 461 events among DPP4 inhibitor users. On matching, there were 156 events over a mean survival time of 3.04 years among SGLT-2 inhibitors and 212 events over a mean survival time of 2.81 years among DPP4 inhibitor users. The adjusted incidence rates (95% CI) per 1000 person-years were 20.90 (95% CI 17.75 to 24.45) for SGLT-2 inhibitor and 29.23 (95% CI 25.42 to 33.44) for DPP4 inhibitor users (table 1).
Rates of new or worsening nephropathy and acute kidney injury among persons exposed to SGLT-2 inhibitors and active comparators
In CPRD, there were a total of 37 events among SGLT-2 inhibitor users and 316 events among DPP4 inhibitor users. On matching, there were 32 events over a mean survival time of 3 years among SGLT-2 inhibitors and 37 events over a mean survival time of 3.33 years among DPP4 inhibitor users. The adjusted incidence rates (95% CI) per 1000 person-years were 15.35 (10.50 to 21.66) for SGLT-2 inhibitor and 19.40 (13.66 to 26.75) for DPP4 inhibitor users (table 1).
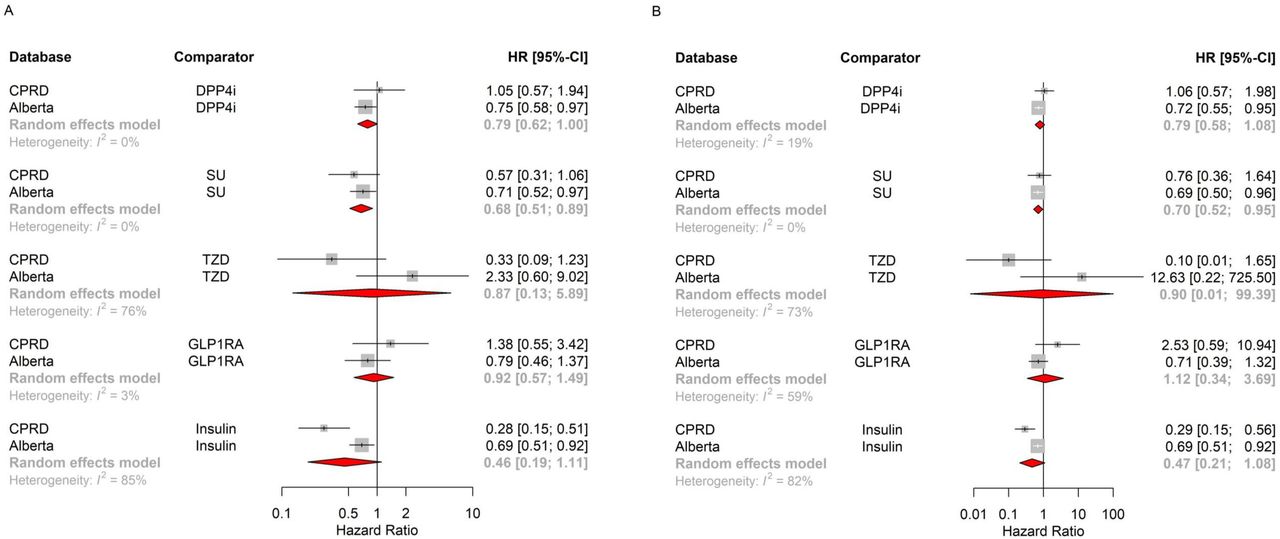
Our random-effects meta-analysis of aggregate data across databases shows SGLT-2 inhibitor initiators are associated with a deceased risk of renal disease progression compared with DPP4 inhibitors (pooled HR 0.79, 95% CI 0.62 to 1.00) (figure 2A). Results were consistent in the direction and magnitude of effect, although with less precision, after further adjustment for age, sex, and previous use of other antidiabetic agents (pooled HR 0.79, 95% CI 0.58 to 1.08; figure 2B). Results become more precise when we used the full GOLD CPRD cohort (pooled HR 0.82, 95% CI 0.68 to 0.98; online supplemental figure 5).

Pooled HR for renal disease progression across databases, using matched-only Cox model without further adjustments (A) and with further adjustment for age, sex, and previous use of other diabetes medications (B). CPRD, Clinical Practice Research Datalink; DPP4-i, dipeptidyl peptidase-4 inhibitors; GLP1-RA, glucagon-like peptide-1 receptor agonists; SU, sulfonylureas; TZD, thiazolidinediones.
On assessing each component of the composite outcome separately and compared with DPP4 inhibitors, SGLT-2 inhibitors were associated with lower risk of hospitalization for new or worsening renal failure (pooled 0.60, 95% CI 0.39 to 0.91), but not with the risk of increase from baseline, defined as the latest laboratory value measured before index date, in 24-hour urinary excretion of albumin to >300 mg OR increase in timed collection to >200 μg/min OR increase in ACR to >20 mg/mmol (pooled 0.84, 95% CI 0.62 to 1.15). There was insufficient power to assess the other components of the renal composite outcome.
Results from our secondary analyses of the different comparator cohorts also show SGLT-2 inhibitors to be associated with a decreased risk of renal disease progression compared with SU (pooled HR 0.68, 95% CI 0.51 to 0.89) (figure 2A). However, the HRs were not significant for TZD (pooled HR 0.87, 95% CI 0.13 to 5.89), GLP1-RA (pooled HR 0.92, 95% CI 0.57 to 1.49), and insulin (pooled HR 0.46, 95% CI 0.19 to 1.11) (figure 2A). These overall associations did not differ after further adjustments for age, sex, and previous use of other antidiabetic agents (figure 2B).
Agent stratified analysis shows that compared with DPP4 inhibitors, both canagliflozin (pooled HR 0.70, 95% CI 0.45 to 1.09) and dapagliflozin (pooled HR 0.80, 95% CI 0.57 to 1.15) had point estimates suggesting a lower risk of renal worsening, however neither result was statistically significant. Empagliflozin was not associated with a lower risk of renal worsening (pooled HR 1.17, 95% CI 0.71 to 1.92).
After stratifying the analysis based on baseline kidney function, the pooled HR for the primary efficacy outcome (composite of new or worsening nephropathy) was 1.03 (95% CI 0.46 to 2.30) for the non-impaired group (≥60 mL/min/1.73 m2) and 1.15 (95% CI 0.55 to 2.43) for the impaired group (<60 mL/min/1.73 m2).
On varying the exposure definition, results were mostly consistent with our primary exposure definition (online supplemental figure 6).
Acute kidney injury
In AB, there were a total of 43 AKI events among SGLT-2 inhibitor users and 155 events among DPP4 inhibitor users. The crude incidence rates (95% CI) per 1000 person-years were 5.56 (4.02 to 7.49) for SGLT-2 inhibitor users and 10.21 (8.67 to 11.94) for DPP4 inhibitor users. On matching, there were 42 events over a mean survival time of 1.99 years among SGLT-2 inhibitors and 63 events over a mean survival time of 2.97 years among DPP4 inhibitor users. The adjusted incidence rates (95% CI) per 1000 person-years were 5.57 (4.01 to 7.52) for SGLT-2 inhibitor and 8.56 (6.58 to 10.96) for DPP4 inhibitor users (table 1).
In CPRD, there were a total of 22 AKI events among SGLT-2 inhibitor users and 220 events among DPP4 inhibitor users. The crude incidence rates (95% CI) per 1000 person-years were 9.16 (5.74 to 13.87) for SGLT-2 inhibitor users and 21.13 (18.43 to 24.12) for DPP4 inhibitor users. On matching, there were 21 events over a mean survival time of 3.04 years among SGLT-2 inhibitors and 22 events over a mean survival time of 3.37 years among DPP4 inhibitor users. The adjusted incidence rates (95% CI) per 1000 person-years were 9.95 (6.16 to 15.20) for SGLT-2 inhibitor and 11.40 (7.14 to 17.26) for DPP4 inhibitor users (table 1).
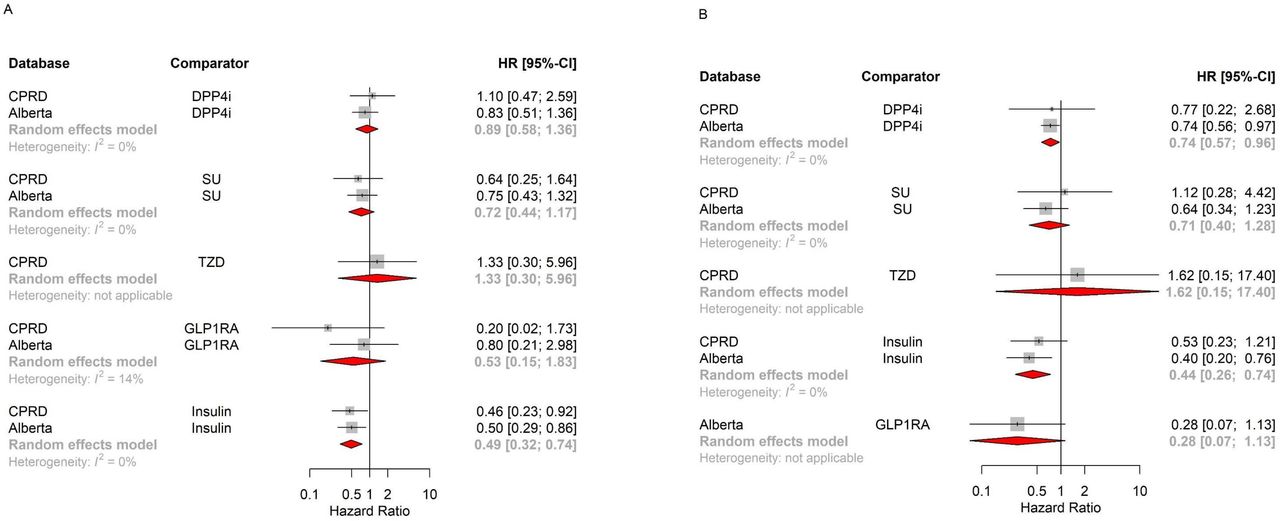
Our random-effects meta-analysis of aggregate data across databases does not show SGLT-2 inhibitors to be associated with significant difference in AKI risk compared with DPP4 inhibitors (pooled HR 0.89, 95% CI 0.58 to 1.36) (figure 3A) when using the matched paired cohort without further covariate adjustment. However, after further adjustment for age, sex, and previous use of other antidiabetic agents SGLT-2 inhibitors were associated with a significantly decreased risk of AKI compared with DPP4 inhibitors (pooled HR 0.74, 95% CI 0.57 to 0.96) (figure 3B).
{kind=link}
{kind=link}
{kind=link}
Pooled HR for acute kidney injury across databases, using matched-only Cox model without further adjustments (A) and with further adjustment for age, sex, and previous use of other diabetes medications (B). CPRD, Clinical Practice Research Datalink; DPP4-i, dipeptidyl peptidase-4 inhibitors; GLP1-RA, glucagon-like peptide-1 receptor agonists; SU, sulfonylureas; TZD, thiazolidinediones.
Results from our secondary analyses of the different comparator cohorts also show SGLT-2 inhibitors to be associated with a decreased risk of AKI compared with insulin (pooled HR 0.49, 95% CI 0.32 to 0.74). However, the HRs were not significant for SU (pooled HR 0.72, 95% CI 0.44 to 1.17) and GLP1-RA (pooled HR 0.53, 95% CI 0.15 to 1.83). These overall associations did not differ after further adjustments for age, sex, and previous use of other antidiabetic agents (figure 3B).
Agent stratified analysis shows that compared with DPP4 inhibitors, none of the SGLT-2 inhibitor agents are associated with a significant difference in risk of AKI (pooled HR 1.19, 95% CI 0.51 to 2.78 for canagliflozin; pooled HR 0.64, 95% CI 0.34 to 1.20 for dapagliflozin; pooled HR 1.99, 95% CI 0.43 to 9.28 for empagliflozin).
After stratifying the analysis based on baseline kidney function, the pooled HR for AKI was 0.68 (95% CI 0.39 to 1.19) for the non-impaired group (≥60 mL/min/1.73 m2) and 1.78 (95% CI 0.49 to 6.48) for the impaired group (<60 mL/min/1.73 m2). On varying the exposure definition, results were consistent with our primary exposure definition (online supplemental figure 7).
Discussion
Our study provides a comprehensive assessment of the real-world effectiveness and safety of SGLT-2 inhibitor use for renal-related endpoints. Given the known limitations of RCTs, including limited data on active comparators, lack of power for safety events, and limited generalizability, providing real-world evidence using an observational study design provides a more comprehensive assessment of drug outcomes. Using a large sample from both Canada and the UK, we found that patients who initiated an SGLT-2 inhibitor were less likely to experience new or worsening nephropathy compared with DPP4 inhibitor initiators and were not at an increased risk of an acute kidney event. These findings add to the body of literature supporting the renoprotective effects of SGTL-2 inhibitors.
Evidence from RCTs has consistently demonstrated that SGLT-2 inhibitors are associated with a reduction of 30%–46% in new or worsening nephropathy compared with placebo.19–21 Moreover, a 2019 meta-analysis of 10 RCTs reported a statically significant lower risk of end-stage renal disease in SGLT-2 inhibitors compared with placebo or active comparators (Relative Risk (RR) 0.70; 95% CI 0.57 to 0.87).22 In line with these results, our population-based observational cohort study confirm the effectiveness and safety of SGLT-2 inhibitors in real-world patients by reducing new renal disease or renal worsening without significant moderation of effect by age, sex, baseline HbA1c levels, or use of other antidiabetic agents in the previous year. We also did not detect a difference in the risk of the renal composite outcome (new or worsening nephropathy) or AKI on stratifying based on the baseline kidney function.
Previous observational studies have also assessed the renoprotective effects of SGLT-2 inhibitors, however using different study populations, methods for confounding control, and importantly outcome definitions.23 24 29 30 Heerspink et al found that SGLT-2 inhibitors were associated with a slower rate of eGFR decline and a lower risk of a composite outcome (50% eGFR decline or end-stage renal disease) compared with other antihyperglycemic medications over a mean follow-up of 14.9 months. Pasternak et al compared new users of SGLT-2 inhibitors to new users of DPP4 inhibitors of which SGLT-2 inhibitor users had a 58% lower risk of serious renal events. Xie et al found SGLT-2 inhibitors to be associated with a lower risk of a composite outcome of eGFR decline >50%, end-stage kidney disease, or all-cause mortality compared with SU (HR 0.68 (95% CI 0.63 to 0.74), DPP4 inhibitors (HR 0.76 (95% CI 0.70 to 0.82), but not GLP1-RA (HR 0.95 (95% CI 0.87 to 1.04)).29 Importantly, our overall findings are consistent with these studies. In another study, Xie et al found new use of empagliflozin to be associated with lower risk of major adverse kidney events (HR 0.68 (95% CI 0.64 to 0.73)) compared with new use of non-SGLT-2 inhibitors.30 We did not reach a similar conclusion for empagliflozin in the agent stratified analysis, although our comparator group was restricted to one class of antidiabetic agents rather than all other non-SGLT-2 inhibitors.
Akin to these studies, we also used a new user design with an active comparator and accounted for confounding using propensity score matching. Our study differed in several respects. First, our base cohort was limited to new metformin monotherapy users, a clinically relevant group that is concordant with multiple clinical practice guidelines.45 46 Second, our study included four other new-user active comparator cohorts beside DPP4 inhibitors. Third, we used high-dimensional propensity score algorithm to identify hundreds of potential confounders (in addition to those identified a priori). Fourth, we have defined an effectiveness composite renal outcome based on the definition that closely resembles that used in RCTs. Lastly, our study used a different population than previous studies, including data from North American from AB, Canada and European data from the UK.
Within the same cohorts, we did not detect an increased risk of AKI in accordance with evidence from clinical trials.16 Although Perlman et al47 reported a threefold higher odds of reporting an acute renal event for SGLT-2 inhibitor users compared with other medications using the US FDA adverse event report system database, this signal was not corroborated by subsequent retrospective cohort studies.25–28 Previous cohort studies have varied substantially in their population size27 28 and age distribution,26 length of follow-up,25 26 composition of control group, and outcome definitions. Our analysis adds to the existing body of evidence and provides reassurance on the renal safety of SGLT-2 inhibitors and suggests that safety warnings by regulatory bodies may not be warranted.
Limitations
Despite the multiple nuances this study adds to complement existing evidence, our study has limitations. First, non-differential misclassification of exposure, which was based on prescription and dispensations records is possible, although biasing results toward the null. Second, both outcome definitions have not been previously validated in these datasets; therefore introducing non-differential misclassification of outcomes. We included diagnostic codes used in existing literature to minimize this issue. Third, despite using an active comparator new user design among new users of metformin and high dimensional propensity score matching, the risk of unmeasured confounding cannot be ruled out. Fourth, our study had limited power to detect effects for each individual SGLT-2 inhibitor. Given the recent approval by the FDA to use canagliflozin and dapagliflozin but not empagliflozin for the treatment of CKD, future analysis using larger datasets to explore intraclass differences in renal effects and safety will be useful. Fifth, there was insufficient power to assess all the components of the renal composite outcome definition separately. Sixth, we were only able to describe the baseline racial and ethnic distributions of patients in CPRD only as AB lacks information on race and ethnicity. Last, we were unable to assess either outcome among those with a baseline eGFR of <60 mL/min/1.73 m2.
In conclusion, using population-based real-world data from North America and Europe, this assessment of both renal effectiveness and safety end points in the same population, provides a comprehensive picture to support the role of SGLT-2 inhibitors in clinical guidelines for diabetes management. Our findings support the renoprotective effects of SGLT-2 inhibitors compared with clinically relevant comparators. Moreover, concerns over increased risk of AKI are not substantiated by our study findings.
Data availability statement
Data may be obtained from a third party and are not publicly available. We are unable to make data available because of third party license restrictions.
Ethics statements
Patient consent for publication
Ethics approval
The study protocol was approved by the University of Alberta’s Human Research Ethics Board (#84111), University of Waterloo’s Research Ethics Board (#31928), and the CPRD’s Independent Scientific Advisory Committee (ISAC 18_205).
Acknowledgments
This study is based in part on data from the Clinical Practice Research Datalink obtained under license from the UK Medicines and Healthcare products Regulatory Agency. The data are provided by patients and collected by the NHS as part of their care and support. The interpretation and conclusions contained in this study are those of the author/s alone. Copyright (2021), re-used with the permission of The Health & Social Care Information Centre. All rights reserved. The OPCS Classification of Interventions and Procedures, codes, terms, and text is Crown copyright (2016) published by Health and Social Care Information Centre, also known as NHS Digital and licensed under the Open Government Licence available at www.nationalarchives.gov.uk/doc/open-government-licence/open-government-licence.htm. This study is based on data provided by The Alberta Strategy for Patient Orientated Research (ABSPOR) SUPPORT unit, Alberta Health, and Alberta Health Services. The interpretation and conclusions contained herein are those of the researchers and do not necessarily represent the views of the Government of Alberta, Alberta Health Services, nor ABSPOR. Neither the Government of Alberta, Alberta Health Services, nor ABSPOR expresses any opinion in relation to this study. The data that support the findings of this study are available from the ABSPOR (https://absporu.ca). We had full permission to use these data, however, restrictions apply to the public availability of these data, which are under data access agreements for the current study.
References
Supplementary materials
Supplementary Data
This web only file has been produced by the BMJ Publishing Group from an electronic file supplied by the author(s) and has not been edited for content.
Footnotes
Contributors J-MG, DTE, and AZ conceived the study idea and all authors contributed to the study design. WA and JKM-S conducted all analyses. WA and J-MG wrote the first draft of the manuscript. All authors contributed to and approved the final version of the article. J-MG will act as guarantor for the study.
Funding This study is funded by the Canadian Institute of Health Research (FRN 156064).
Disclaimer The funder of the study had no role in study design, data collection, data analysis, data interpretation, or writing of the report. The corresponding author had full access to all the data in the study and had final responsibility for the decision to submit for publication.
Competing interests None declared.
Provenance and peer review Not commissioned; externally peer reviewed.
Supplemental material This content has been supplied by the author(s). It has not been vetted by BMJ Publishing Group Limited (BMJ) and may not have been peer-reviewed. Any opinions or recommendations discussed are solely those of the author(s) and are not endorsed by BMJ. BMJ disclaims all liability and responsibility arising from any reliance placed on the content. Where the content includes any translated material, BMJ does not warrant the accuracy and reliability of the translations (including but not limited to local regulations, clinical guidelines, terminology, drug names and drug dosages), and is not responsible for any error and/or omissions arising from translation and adaptation or otherwise.